It's got 45,433 words (tokens), 5,971 unique words (types), and 5,688 lemmas (like, conjugated versions of the same word? I guess that's how I would describe a lemma).
I compared the Kate in Jordan corpus with the LOB corpus because I had it loaded into the tool I was using already. It is a million word corpus designed to be the British counterpart to the Brown Corpus, which is a pretty well-known, well-used corpus of American English that is getting a bit old. It was built in 1961.
I then compared the Kate in Jordan corpus against the Brown corpus itself.
The point: I was trying to figure out what the keywords of my corpus are, and to do that you have to compare it against a different corpus. Keywords show the "aboutness" of a text. They are the words that appear more proportionally in one text than in another.
Here are the top 57 important keywords of my corpus. I am not including possessive pronouns, contractions, words like "very" and "really" etc. They might be interesting to study at some point, but not right now. I am also only including words that are in English.
1. arabic
2. jordan
3. arab
4. mom
5. iraq
6. trevor
7. language
8. phone
9. pierrick
10. hibba
11. branch
12. love
13. blog
14. internet
15. mormon
16. family
17. jordanian
18. israel
19. culture
20. sanaa
21. byu
22. irbid
23. understand
24. muslim
25. feel
26. computer
27. marry
28. airport
29. arabs
30. muslims
31. kate
32. france
33. sim
34. stupid
35. amman
36. rennes
37. weird
38. french
39. photos
40. bathroom
41. democracy
42. middle
43. sisters
44. funny
45. americans
46. hammouri
47. nedal
48. palestinians
49. yarmouk
50. here
51. stuff
52. english
53. friend
54. learn
55. dad
56. myself
57. think
Here is how I would categorize these words:
about language
1. arabic
7. language
38. french - though this could be an adjective
52. english

about places
2. jordan
5. iraq
11. branch
18. israel
21. byu
22. irbid
28. airport
32. france
35. amman
36. rennes
40. bathroom
49. yarmouk
50. here

about people
4. mom
6. trevor
9. pierrick
10. hibba
16. family
20. sanaa
30. muslims
31. kate
43. sisters
45. americans
46. hammouri
47. nedal
48. palestinians
55. dad
56. myself

about identity
3. arab
15. mormon
17. jordanian
19. culture
24. muslim
29. arabs
34. stupid
37. weird
41. democracy
44. funny
53. friend

about technology
8. phone
13. blog
14. internet
26. computer
33. sim
39. photos
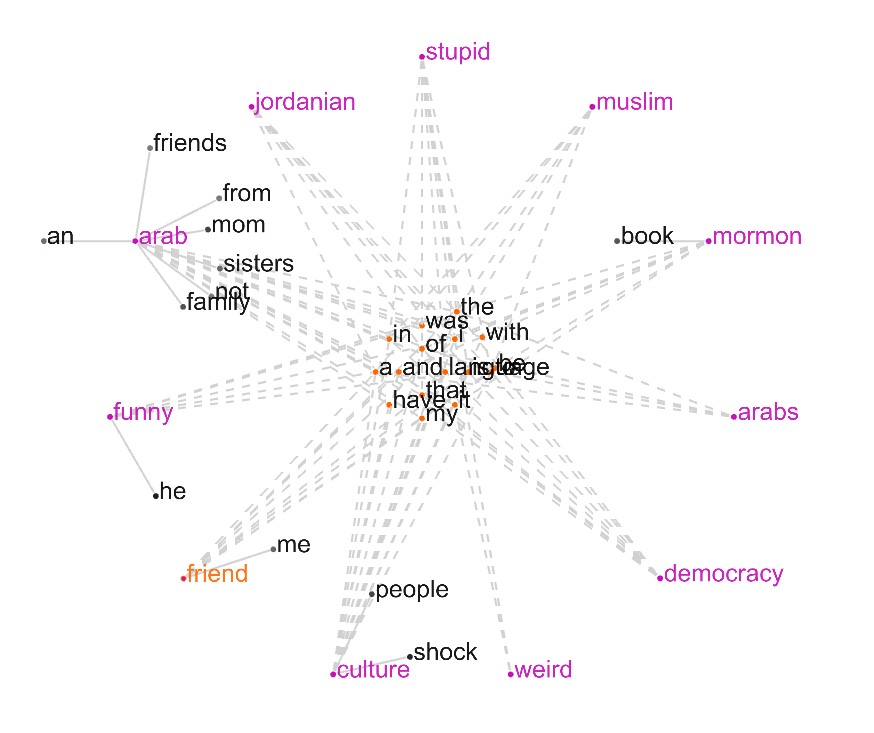
abstract verbs
12. love
23. understand
25. feel
27. marry
54. learn
57. think

outliers
42. middle - probably from "middle east"
51. stuff - I guess this is a word I use comparatively a lot.


Huh. I'm still scratching my head on this one. It is not really apparent to me what this word is about.
Here are some of the sentences with the word "love" in it.


This last thing is the actual top 10 key words when you compare my blog with the Brown corpus. My, my. Kinda interesting.
Danny appeared twice in all 45k words, while Trevor (the at-the-time love interest) appeared 33 times. Sheesh Kate.
So. In the end of playing around with this for a little while - I learned a few things:
1. This is really fun.
2. I still don't know what new, revealing information this tells me about anything. Like, duh. My blog was mostly about language, places, identity, and people. I could have told you that without running any statistical analysis on it whatsoever. It's cool to see it quantified, but what does the data mean? Dunno. YET.
3. I have to think more carefully about what this analysis is doing. Because clearly, frequency of words does matter, but it isn't all-important.
4. I have to learn more about what these tools can do.
5. The visualizations are *by far* the funnest part. But see point #3.
I'm so insulted and jealous :p
ReplyDeleteHa. I think you will win in the final version of the Kate Corpus, sweetie.
Delete